5年以上apahce使ってるけどKeepAliveの設定ってあまり気にすることなかった。ていうか、そこまで巨大なサービスを運用する機会がなかったからとりえずonにしとけばいいんじゃね!?ぐらいなもんではい。。。
では、実際になぜKeepAliveが必要なのかhttpの仕様をみながらお話していきます。
注)KeepAliveはHTTP/1.1より実装された機能なので以下はHTTP/1.1を前提にお話いたします。
apacheをスレッドベースで動作させる方法もありますが、プロセスベースで検証します。
httpはステートレス・プロトコル
ステートレス・プロトコル(stateless protocol)とは状態を持たないプロトコルのことで、必要なレスポンスをかえしたら即時に切断される。サーバ側はどこの誰がリクエストしているかも知らないし、クライアントがどういう状態かもわからない。
つまり一人の人が100回アクセスしてこようがサーバー側では100回違う人がアクセスしてきてるという認識だ。
逆に状態を持つプロトコルでステートフル・プロトコル(stateful protocol)というものもある。
例えば、FTPは任意のホスト間のファイル転送を行いますが、クライアントからの接続要求によって通信が開始され、クライアントから明示的に切断要求がない限り通信状態が保持される。
一度接続を確立すると「あのファイルが欲しい」「このファイルをアップロードしたい」「ファイルを削除したい」等の処理を対話的に行う。
特定少数のユーザーしか使わないのに、通信のリクエストが入る度に認証処理をしてたら効率が悪いですね。
「えぇーーでもECサイトとかだとログイン状態保持してんじゃん!」
それは毎回クライアントから私こういうものですけどーっていうID(SESSION ID)を渡しつづけているからなのです。
そのIDをもとにサーバー側であー○○さんね!
てなかんじでリクエストの度にクライアントからIDを渡すことで、擬似的にステートフルなサービスを実現している。
なぜhttpはステートレスなのか?
ステートフルはクライアントが明示的に切断しないと接続が残りつづけるので、webページみたいな不特定多数からのアクセスに対しては不向きだ。
仮にhttpがステートフルだったら100万アクセスあったら100万個のコネクションを維持しないといけなくなる。。。
これではリクエストをさばききれないので、うけたらさっさと切断してしまったほうがいいわけです(笑)
実際のお店で例えてみる
webページってcssとかjsとか画像とか1ページ読み込むだけでたくさん通信してるし、ECサイトなんかだと購入途中でつながりにくくなるのも嫌だからやっぱりある程度接続しててもらったほうがいいんじゃない?
実際にお店で買い物をした場合で例えてみよう。
大行列の10人はいるお店で何かものを買おうとしたとき、商品を手にするたびに最後尾から並びなおすということがおきたらどうだろう?
買う気失せますね(笑)
そこで一時的にコネクションを維持しといてあげるよっていうのがKeepAliveだ。
○KeepAliveの設定項目
・KeepAlive On
接続を維持するかどうか
・MaxKeepAliveRequests 100
接続してから切断するまでに受け付けるリクエストの数
(商品100個とったら強制退出させるわ数)
・KeepAliveTimeout 15
接続しているセッションからのリクエストが来なくなってから切断するまでの待ち時間
(最後に商品を手にしてから15秒たったら強制退出させるわ秒数)
通信の状態を確認
実際にKeepAliveを設定した場合にサーバー側でコネクションが維持されているのかを確認したいと思う。
○検証内容
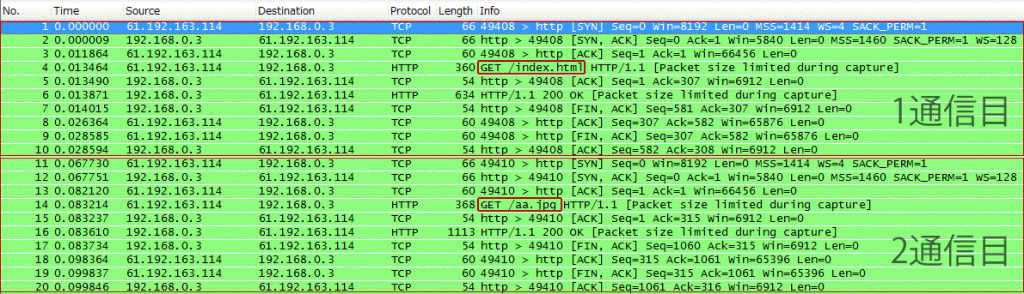
・画像(aa.jpg)を一つだけ埋め込んだindex.html にアクセスし、index.htmlの読み込みに1通信、画像の読み込みに1通信、計2通信を発生させKeepAliveがOnの時にコネクションが使い回されているかどうか確認する。
※KeepAliveの設定は上記であげているがここでは純粋にコネクションの動きだけを見たいので、KeepAliveのOnとOffだけで違いをみることにします。
※apacheの設定のみでKeepAliveを無効にできない(1つのコネクションでいくつリクエストを処理するかはブラウザ依存のため)ため、curlにて検証
■KeepAlive Off
【netstat実行結果】
1
2
3
| Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 ::ffff:192.168.0.3:http XXXX.XXXX.XXXX.XXXX:62207 TIME_WAIT
tcp 0 0 ::ffff:192.168.0.3:http XXXX.XXXX.XXXX.XXXX:62209 TIME_WAIT
|
【パケットキャプチャ】
■KeepAlive On
【netstat実行結果】
1
2
| Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 ::ffff:192.168.0.3:http XXXX.XXXX.XXXX.XXXX:62134 ESTABLISHED
|
【パケットキャプチャ】

上記の結果からKeepAlive Onの時はTCPコネクションが再利用され、KeepAlive Offの場合は通信ごとにTCPコネクションがはられていることがわかる。
所感
1ページあたりの読み込むファイル数が多いページは リクエスト可能回数(MaxKeepAliveRequests)、コネクションを維持する秒数(KeepAliveTimeout)を少し長目にとるとかするといいのかも。
設定はサイトによって柔軟に変更するといいと思います。