はじめに
本年もよろしくお願いいたします🎍
毎年、年末には何かしら新しい学びをインプットする時間を作っているのだが、
今年は諸々の事情で年内に間に合わず、年始から勉強を始めることに!
仕事上Rustに触る機会がなく、明確に「これを作りたい」というテーマもなかったのだが、
せっかくなので「低レイヤーで何か作りたい」という気持ちを優先することにしました。
そこで以前から一度やってみたかった、TCPの3ウェイハンドシェイクをRaw Socketで実装することに挑戦してみた。
HTTPなどのアプリケーション層のプロトコルは一切使わず、
トランスポート層(L4)で直接通信し、文字列を返すだけのシンプルなサーバーを作る。
いわゆる「エコーサーバー」をL4だけで完結させるというのが今回のテーマです。
完成形はこれ:
1 | $ echo "toppage" | nc 172.17.0.2 8888 |
シンプルだけど、これを実現するまでにTCPの仕組みを体系的に理解できた。
一点注意としては、本件は実用性は全く意識しておらず、ハードコーディングのオンパレードです。
何を作ったか
L4 String Server - トランスポート層で文字列を返すだけのサーバー
- Raw Socketで実装
- TCP 3ウェイハンドシェイク(SYN, SYN-ACK, ACK)
- データパケットの送受信
使用技術:
- Rust (初めて)
- Raw Socket (libcでシステムコール呼び出し)
- Docker (macOSのloopback制限回避)
- Claude Code(Agentic codingで学びを加速🙇)
作った経緯
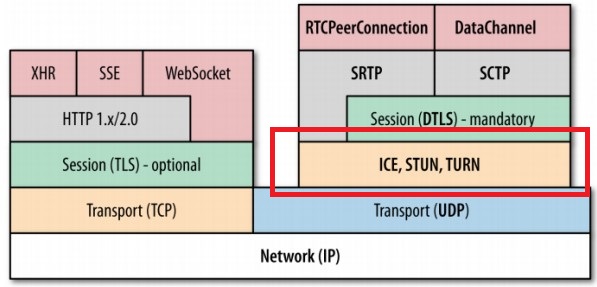
OSI参照モデル見るたびに「アプリケーション層を通さずに3ウェイハンドシェイクの検証ってできないんだっけ?」とずっと思った時期があったので、実験的な意味も含めてやってみたかった。
よく見るこの図の赤枠部分だけでデータやり取りするという試み。
この辺は先人の方々がすでにやられているがあくまでRustの理解を深めるというモチベーションで頑張る。

いざ開発
1. IPヘッダーの解析
IPヘッダーの仕様理解(RFC 791)と受信したパケットからIPヘッダーをパースする。
IPヘッダーの構成
このアスキーアートはAIで出力。
難しい。
1 | 0 1 2 3 |
1 | | バイト位置 | フィールド | 説明 | |
受信したパケットからIPヘッダーをパース
重量なのは送信元IPアドレス、宛先IPアドレス
1 | struct IpHeader { |
ビット演算でバージョンとヘッダー長を取り出す。
2. TCPヘッダー解析
TCPヘッダーの理解(RFC 793)とパース。
TCP ヘッダーの構成
1 | 0 1 2 3 |
1 | | バイト位置 | フィールド | 説明 | |
TCP ヘッダーのパース
1 | struct TcpHeader { |
フラグ判定が重要
1 | const TCP_FIN: u8 = 0x01; // もう送るデータはありません |
3. SYN-ACKパケット作成
ここが一番ハマった。
問題1: カーネルがRSTを送ってくる
SYNを受信してSYN-ACKを返そうとすると、カーネルが勝手にRSTパケットを送信してしまう。カーネルから見ると「知らないポートへのSYN」なので、RSTで拒否するのは正しい動作。
解決: iptablesでRSTをブロック
これでカーネルのRSTを破棄できた。
実用性皆無。
1 | iptables -A OUTPUT -p tcp --tcp-flags RST RST --sport 8888 -j DROP |
問題2: SYN-ACKがeth0に出る
SYNはloインターフェースから来るのに、SYN-ACKがeth0から出て行ってしまう。
解決: 送信用ソケットをloにバインド
受信用と送信用でソケットを分けることで解決。
これまた実用性皆無。
1 | unsafe fn create_send_socket() -> Result<c_int, String> { |
4. チェックサム計算
IPとTCPのチェックサムを計算する必要がある。
1 | fn calculate_checksum(data: &[u8]) -> u16 { |
TCPは疑似ヘッダーを含めてチェックサムを計算する:
1 | fn calculate_tcp_checksum(src_ip: &[u8; 4], dst_ip: &[u8; 4], tcp_segment: &[u8]) -> u16 { |
5. データパケット送受信
コマンドを受け取って、レスポンスを返す部分。
1 | // コマンド受信 |
6. FIN処理 (最後の仕上げ)
最初はncが終了しなかった。
問題: ncが終了を待っている
データを受信しても、ncは接続を閉じずに待機していた。
1 | 1. nc → サーバー: "toppage" (PSH+ACK) |
解決: サーバーからFIN-ACKを送る
データレスポンス送信直後に、サーバーからFIN-ACKを送ることで解決。
1 | // データ送信 |
これでncが自動終了するようになった!
1 | $ echo "toppage" | nc 172.17.0.2 8888 |
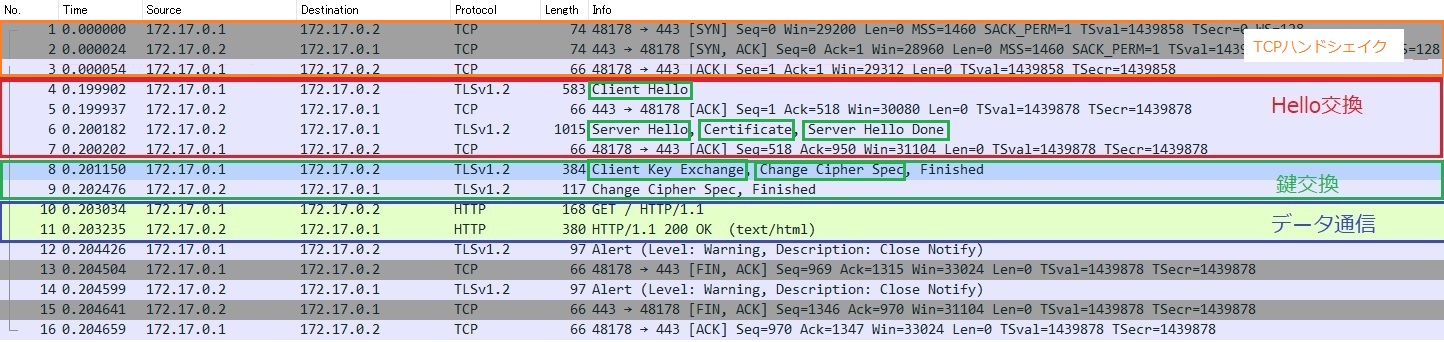
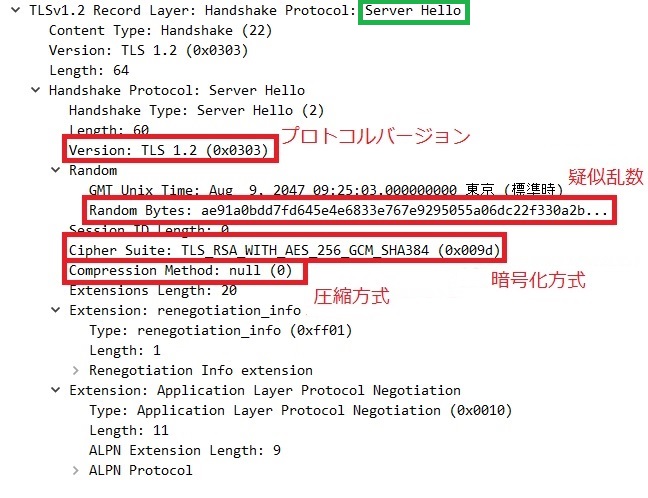
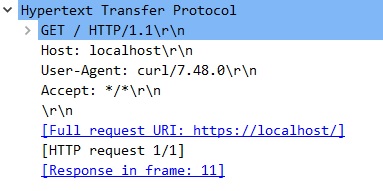
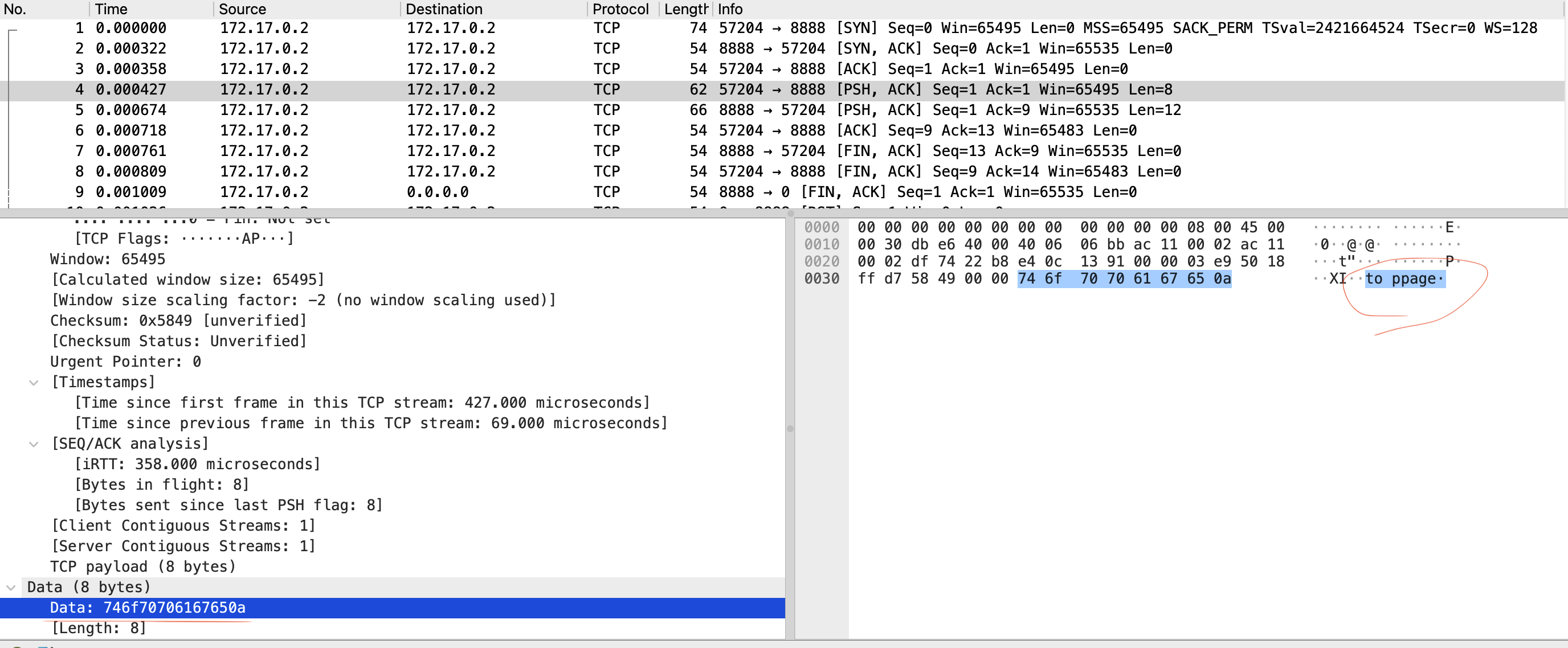
入力のパケットをWiresharkで確認
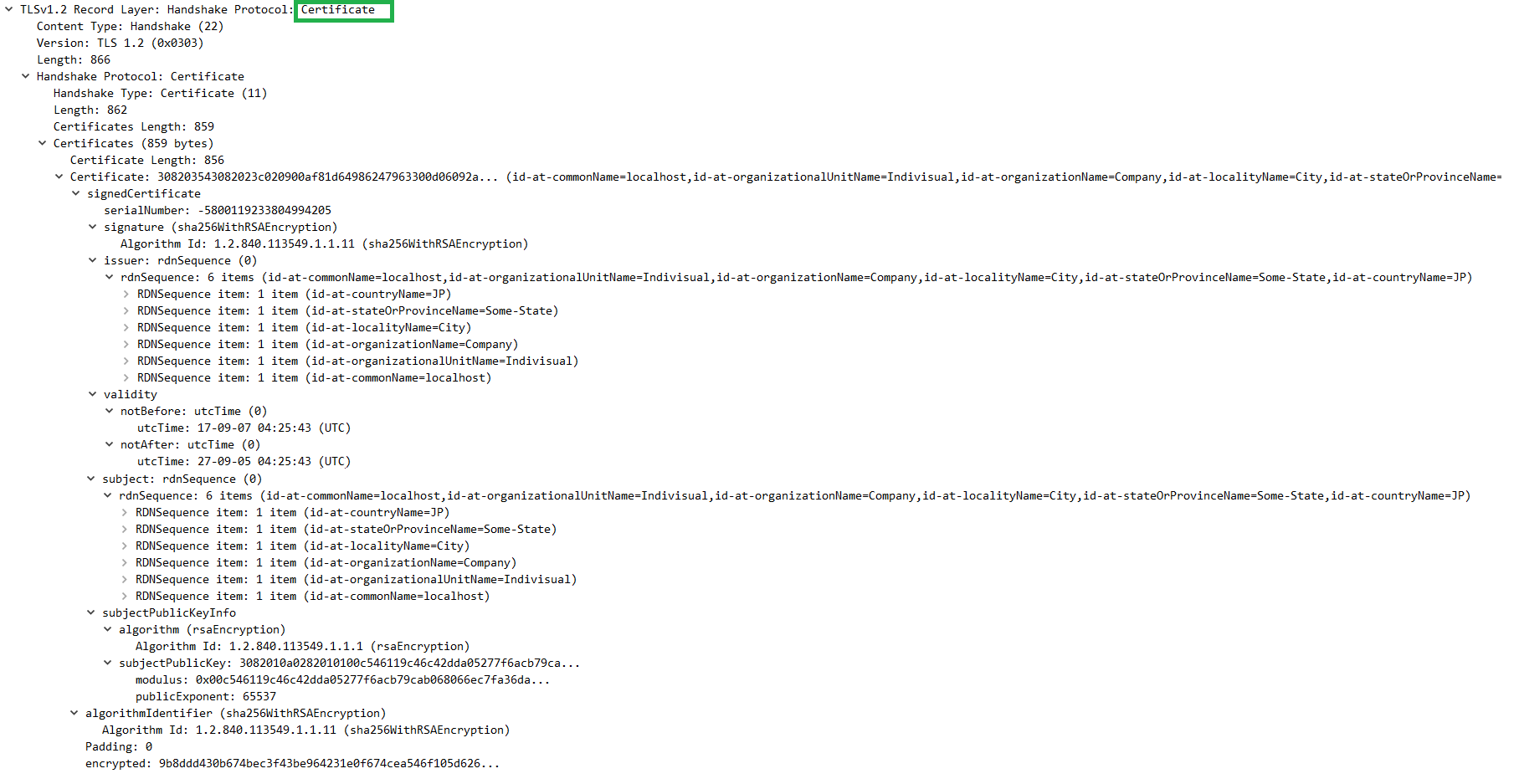
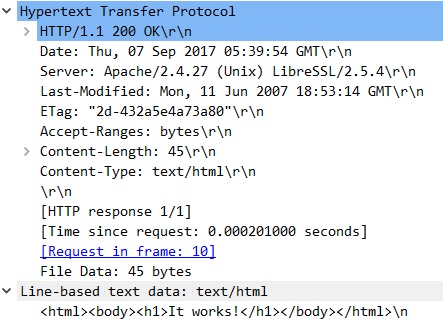
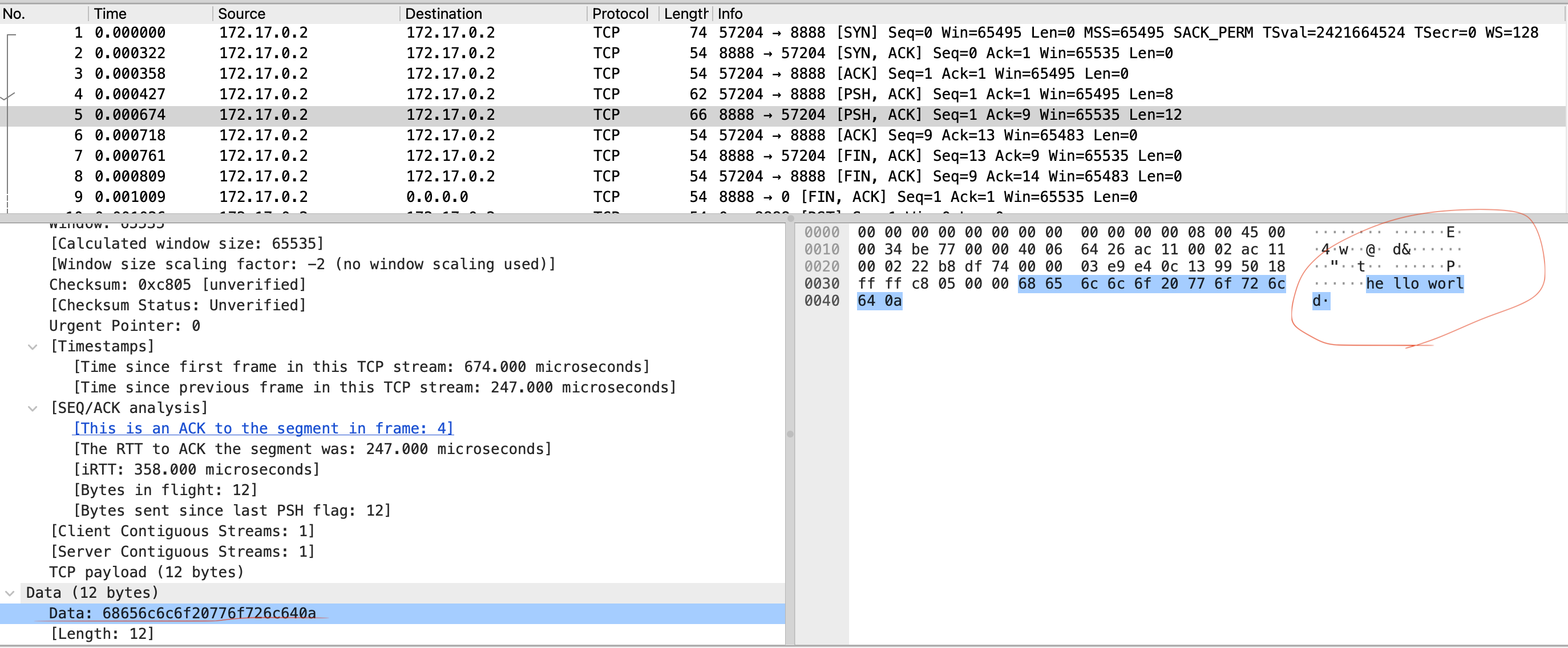
出力のパケットをWiresharkで確認
最終的なパケットフロー
%%{init: {'theme':'forest'}}%%
sequenceDiagram
participant Client as クライアント(nc)
participant Kernel as Linuxカーネル(TCPスタック)
participant Program as プログラム(Raw Socket)
Note over Client,Program: ① 3ウェイハンドシェイク
Client->>Kernel: SYN (lo)
Kernel->>Program: SYN
Note right of Program: 受信
Kernel--xClient: RST (blocked!)
Note left of Kernel: iptablesで破棄
Note right of Program: SYN-ACK作成
Program->>Client: SYN-ACK (lo)
Note right of Program: 送信
Client->>Kernel: ACK (lo)
Kernel->>Program: ACK
Note right of Program: 受信
Established
Note over Client,Program: ② データ交換
Client->>Kernel: PSH+ACK ("toppage") (lo)
Kernel->>Program: PSH+ACK ("toppage")
Note right of Program: 受信
コマンド解析
Program->>Client: PSH+ACK ("hello world") (lo)
Note right of Program: 送信
Client->>Kernel: ACK (lo)
Kernel->>Program: ACK
Note right of Program: 受信
Note over Client,Program: ③ 接続クローズ
Program->>Client: FIN+ACK (lo)
Note right of Program: 送信
接続リセット
Client->>Kernel: FIN+ACK (lo)
Kernel->>Program: FIN+ACK
Note right of Program: (無視)
Note left of Client: 終了
Note over Kernel: 無視
Note right of Program: 次の接続待機
学んだこと
Rustの基本的な構文(構造体、パターンマッチ、Option<T>、テスト)は触ってて楽しかった。
TCPの3ウェイハンドシェイクは理論では知ってたけど、実装してみるとシーケンス番号とACK番号の管理が思ったより重要だった。チェックサム計算も疑似ヘッダー含めて計算する必要があって、細かい仕様が多い。
ハマったポイントは:
- macOSのloopback制限でDocker使った
- カーネルが勝手にRST送ってくるのをiptablesでブロック(実用性皆無)
- 送信パケットがeth0に出ちゃうのを送信用ソケット分離で解決(これも実用性皆無)
- ncが終了しない問題はサーバーからFIN送って解決
おわりに
最初は「SYNパケット受信してSYN-ACK返すだけでしょ?」って思ってたけど、予想外に面倒だった。でもWiresharkでパケット見ながら「ちゃんと動いてる!」ってなるのは楽しい。
ということでRustを学んでいきました〜
仕事でも活用していきたい〜